Kusto Detective Agency — Ready to Play (Part 4 of 5)

While browsing twitter, I came across Kusto Detective Agency — a gamified way of learning Kusto Query Language (KQL).
There are a set of five challenges that participants are required to solve using their KQL skills and earn badges. Challenges are in the form of cases that need to be investigated by a detective agency (the storyline is awesome :P)
To start, participants are required to create a free Kusto cluster and separate data ingestion scripts are provided on a case to case basis.
Challenges
Ready to Play
— — — — — — —
We start with a small mathematical challenge that requires us to find the largest special prime under 100M
A prime number is said to be Special prime number if it can be expressed as the sum of three integer numbers: two neighboring prime numbers and 1. For example, 19 = 7 + 11 + 1, or 13 = 5 + 7 + 1.

We are also given a list of prime numbers. In this case we need to create the ingestion script by ourselves.
.execute database script <|
//Create table for the data
.create-merge table PrimeNumbers(Number:long)
//Import data
.ingest into table PrimeNumbers ('https://kustodetectiveagency.blob.core.windows.net/prime-numbers/prime-numbers.csv.gz')
Once the data has been ingested let’s check the row count.

PrimeNumbers
| countThe underlying idea to get the a list of special primes is — for every row (prime number) in the PrimeNumbers table, find the previous row element (which will also be a prime number) and add both of them and increment the sum by one. If the resulting value is a prime number then we it is a special prime (since it is a sum of two neighboring primes and 1)
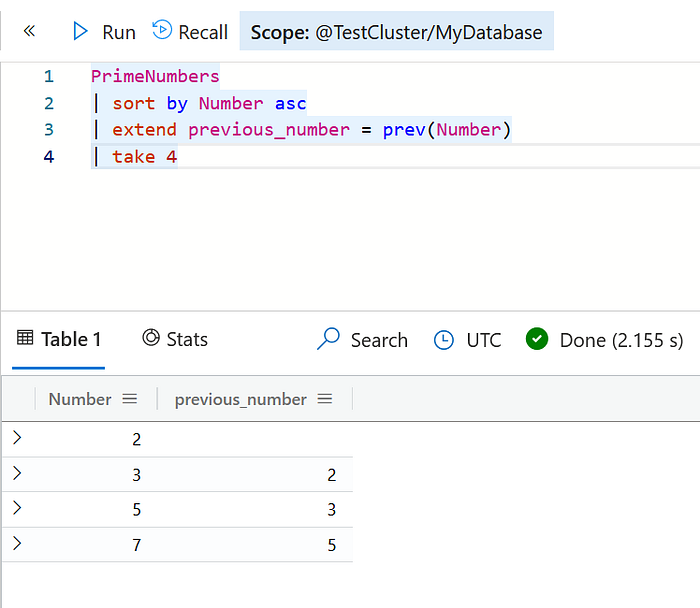
We use the prev() function in KQL to get the value of the previous row element.
PrimeNumbers
| sort by Number asc
| extend previous_number = prev(Number)
| take 4We will now create a new column in the PrimeNumbers table that will be populated as primenumber + prev(prime number) + 1
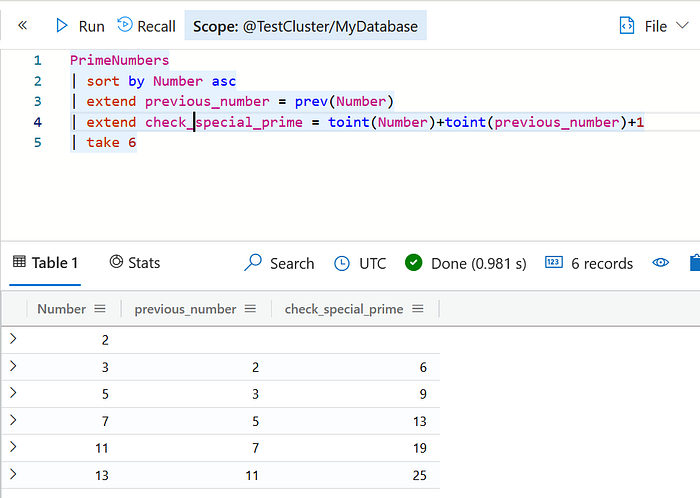
PrimeNumbers
| sort by Number asc
| extend previous_number = prev(Number)
| extend check_special_prime = toint(Number)+toint(previous_number)+1
| take 6And since we know that the largest special prime number < 100M will be more or less in the range of 99M — 100M we can optimize our query by only filtering for special_primes in that range
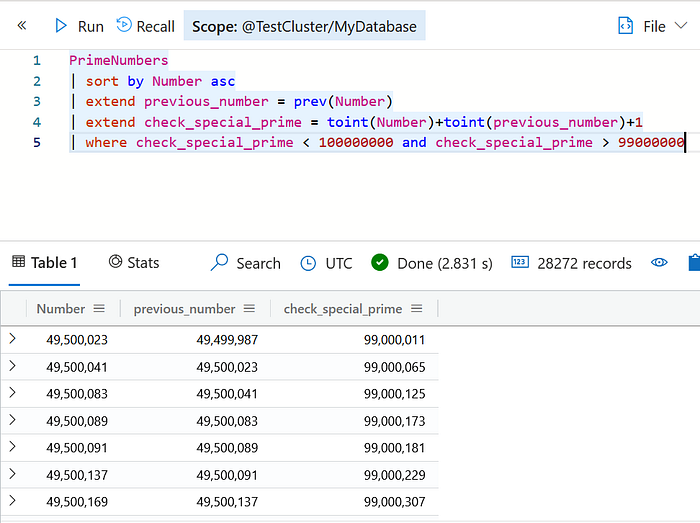
PrimeNumbers
| sort by Number asc
| extend previous_number = prev(Number)
| extend check_special_prime = toint(Number)+toint(previous_number)+1
| where check_special_prime < 100000000 and check_special_prime > 99000000As the final step, we must perform the primality check for entries in the newly created column. For that, we will join the resulting table with the original PrimeNumbers table based on the check_special_prime column to filter out only those entries where the column entry is a prime number (criteria for special prime)
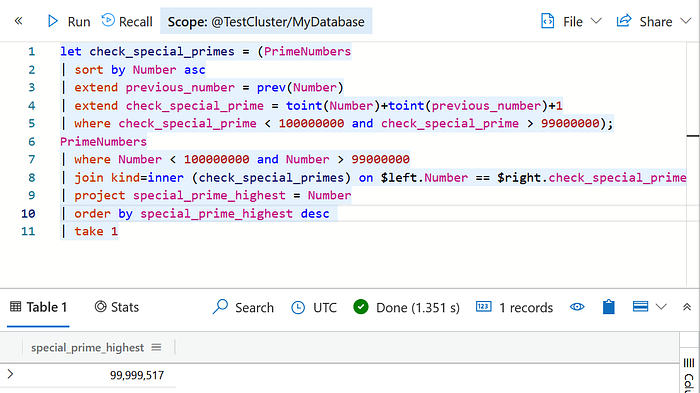
let check_special_primes = (PrimeNumbers
| sort by Number asc
| extend previous_number = prev(Number)
| extend check_special_prime = toint(Number)+toint(previous_number)+1
| where check_special_prime < 100000000 and check_special_prime > 99000000);
PrimeNumbers
| where Number < 100000000 and Number > 99000000
| join kind=inner (check_special_primes) on $left.Number == $right.check_special_prime
| project special_prime_highest = Number
| order by special_prime_highest desc
| take 1Now that we have the largest special prime — 99,999,517, let’s visit the URL specified in the challenge — aka.ms/99999517
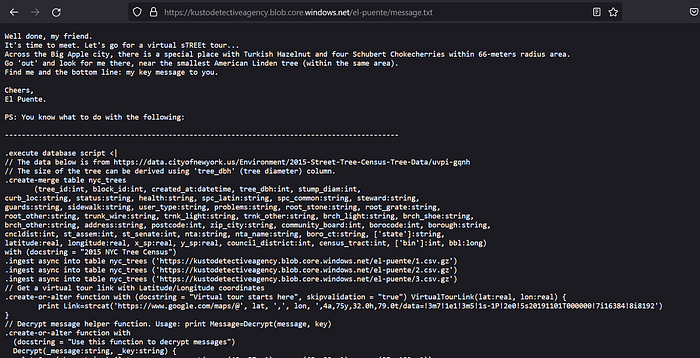
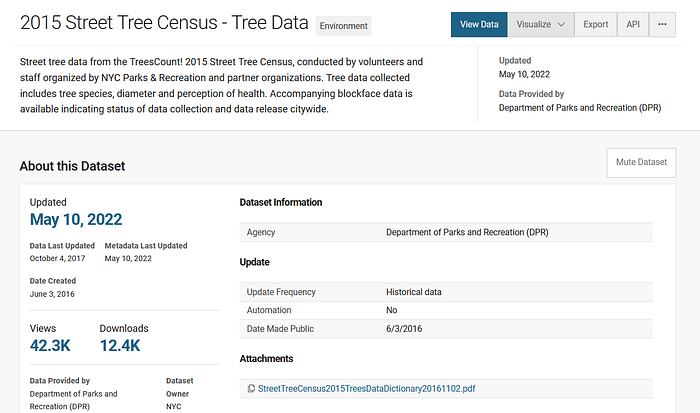
We have a new challenge. We are given street tree census data for NYC which includes parameters like geolocation, tree species, diameter and perception of health etc.
Additionally we are given a function VirtualTourLink that maps any coordinate (latitude, longitude) to Google Maps Street View and allows us a full 360 degree virtual tour of the area.
We also have a Decrypt function that can be used to decrypt messages. Perhaps we need the key to decrypt the encrypted message present in the challenge description.
The final aim is to locate a 66-meters radius area which should contain at least one Turkish Hazelnut tree and four Schubert Chokecherries trees and find the smallest American Linden tree in the same area.
Before we go ahead, let me introduce a very interesting concept- H3 (Uber’s Hexagonal Hierarchical Spatial Index). This is an geospatial indexing system that partitions the entire world into hexagonal cells. It includes functions for converting from latitude and longitude coordinates to the containing H3 cell, finding the center of H3 cells etc.
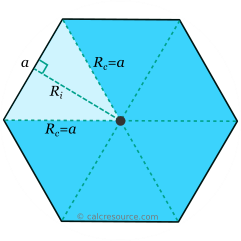
KQL has an inbuilt function —geo_point_to_h3cell(longitude, latitude, resolution) which returns the H3 Cell token value for a given geographic location. From the docs we know that a resolution value 10 indicates indexed by a hexagon with edge length 66m.
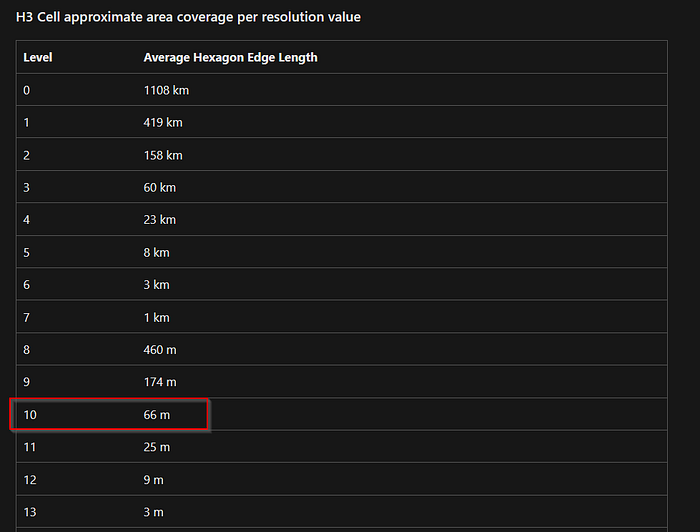
And since we know that for a regular hexagon, edge length (a) is the same as circumradius (Rc), we can approximately say that all geolocations within a circle of 66 m radius will have the same h3 cell value.
So our problem statement boils down to find a h3 cell which has ≥1 hazelnut trees and ≥4 chokecherry trees and >1 American linden tree.
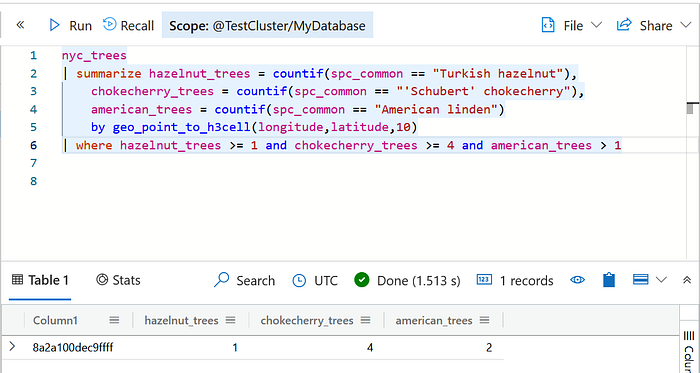
nyc_trees
| summarize hazelnut_trees = countif(spc_common == "Turkish hazelnut"),
chokecherry_trees = countif(spc_common == "'Schubert' chokecherry"),
american_trees = countif(spc_common == "American linden")
by geo_point_to_h3cell(longitude,latitude,10)
| where hazelnut_trees >= 1 and chokecherry_trees >= 4 and american_trees > 1Now that we have the h3 cell index, we need to find the smallest American Linden tree within the h3 cell. For that we will sort all American linden trees in the cell by diameter and find the location of the smallest one.
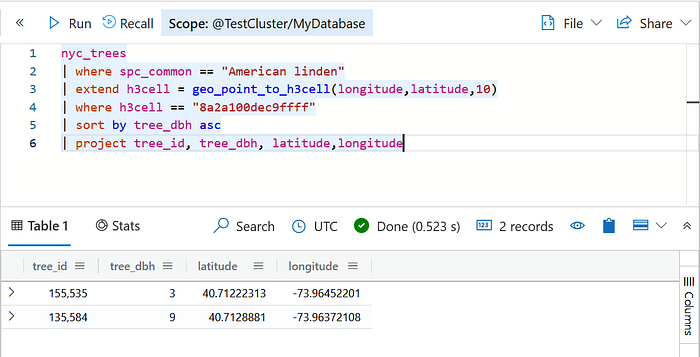
nyc_trees
| where spc_common == "American linden"
| extend h3cell = geo_point_to_h3cell(longitude,latitude,10)
| where h3cell == "8a2a100dec9ffff"
| sort by tree_dbh asc
| project tree_id, tree_dbh, latitude,longitudeFinally we will feed the (latitude,longitude) into the VirtualTour function which will open up Google Street View.
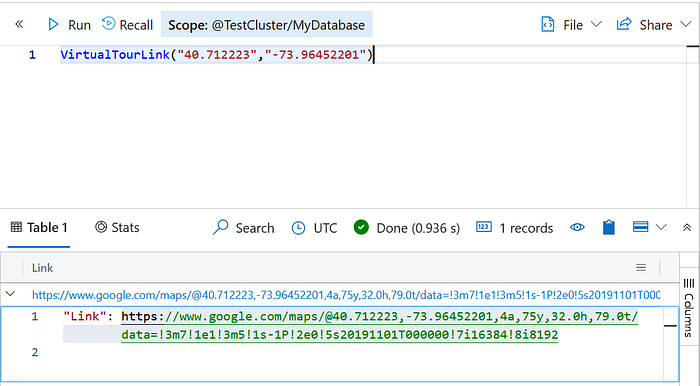
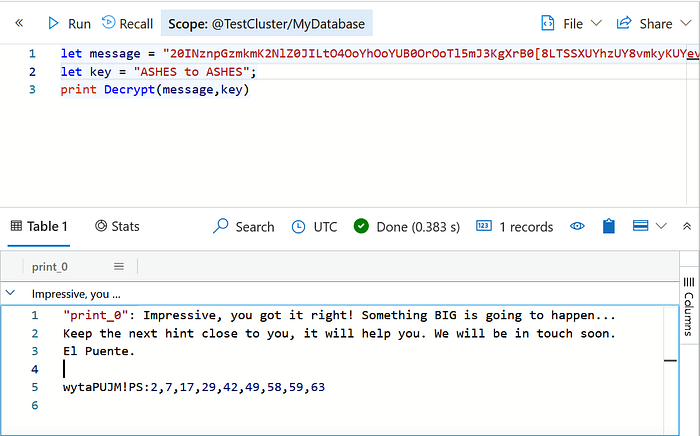
After roaming around for a while, we find this graffiti on the wall — EL PUENTE Ashes to Ashes.

Using this string as a key we are able to successfully decrypt the message using the Decrypt function.
PS: I started learning KQL recently, feel free to reach out to me and correct me, incase you spot some inconsistencies I would highly appreciate that. And finally thank you very much for taking your time to read this post.
